Showing 120 of 120on this page. Filters & sort apply to loaded results; URL updates for sharing.120 of 120 on this page
How to get INT8 calibration cache format in TensorRT? · Issue #625 ...
How to quant TFLite model in int8 format · Issue #36872 · tensorflow ...
YOLOv8 export TensorRt INT8 format ‘dynamic axes will be enabled by ...
How to Save Multiple Files with Specific IDs in int8 Format Using ...
unable to convert yolov8n.pt into tflite int8 format · Issue #11722 ...
Raspberry Pi AI: YOLOv8s Object Detection with Int8 Format Using M.2 ...
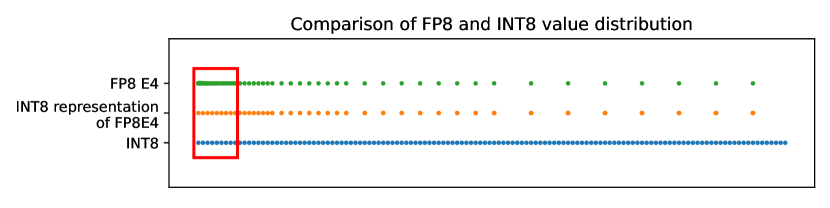
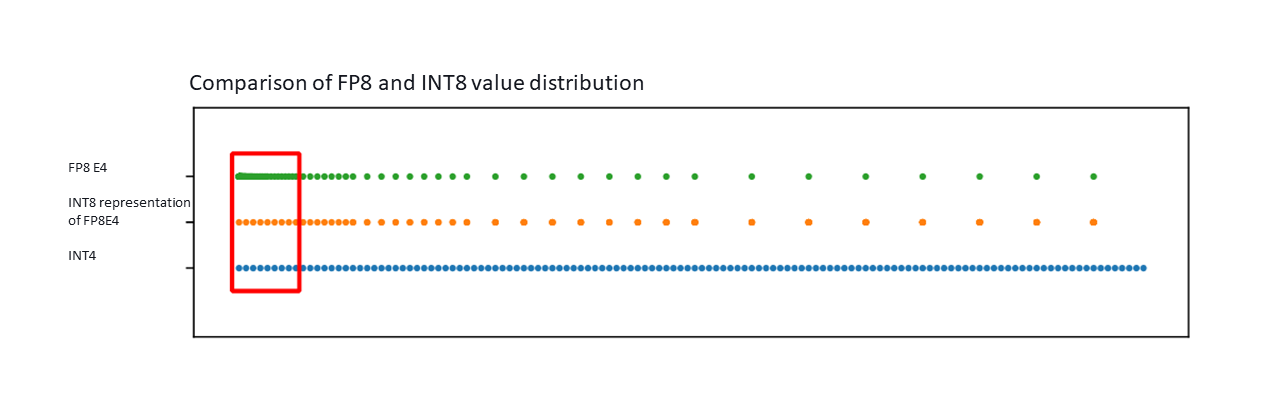
[2303.17951] FP8 versus INT8 for efficient deep learning inference
Matlab saturation arithmetic, int8, format commands - YouTube
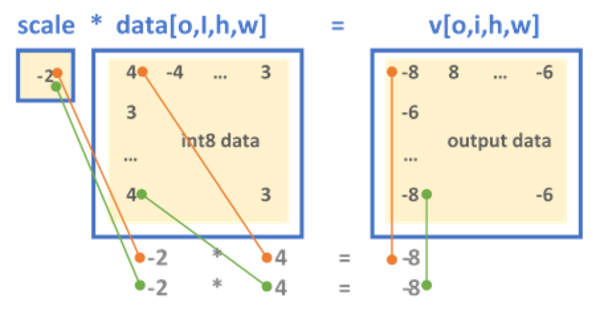
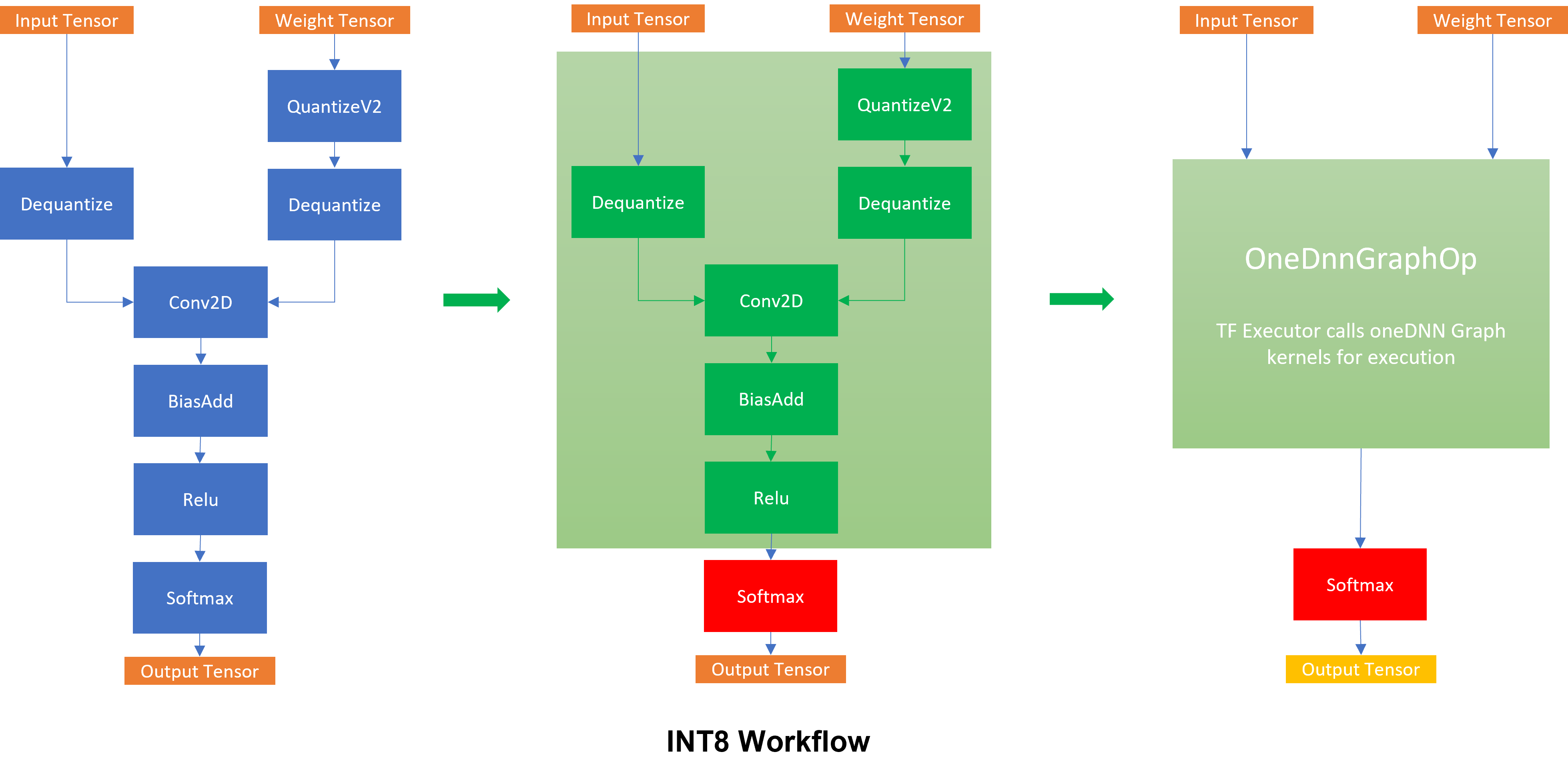
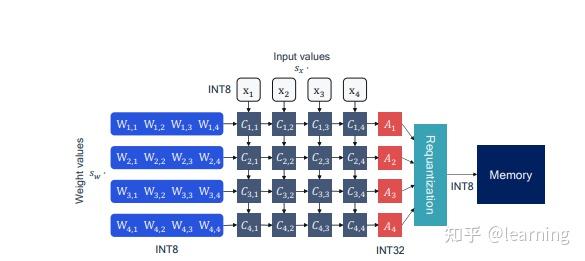
Int8 Inference
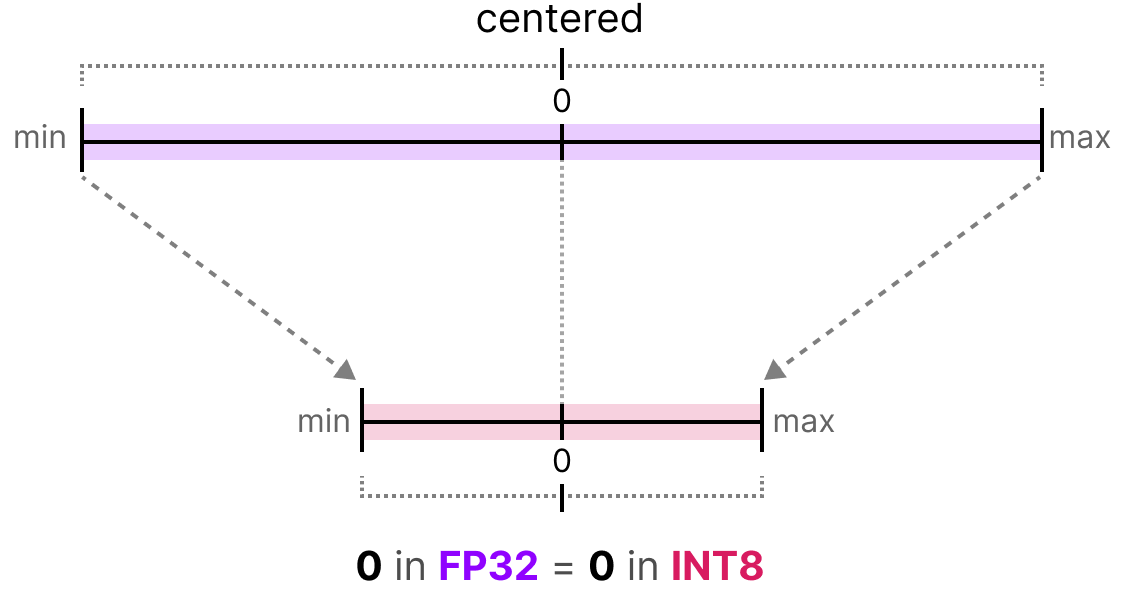
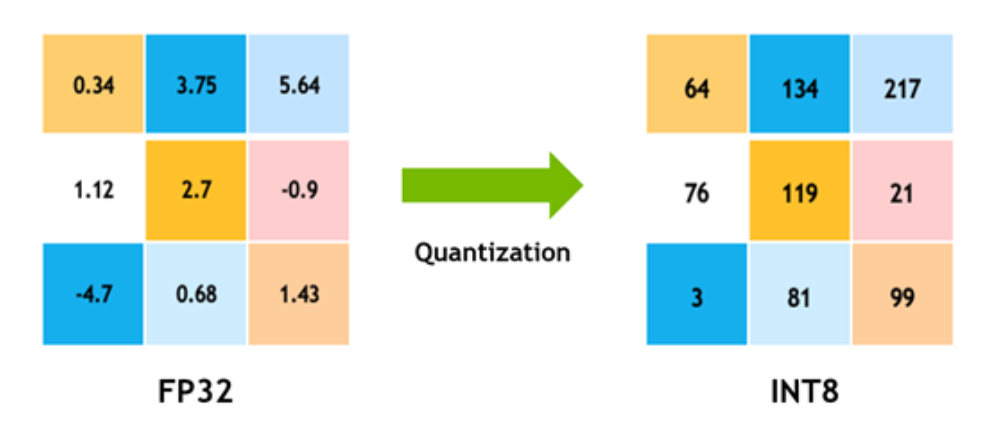
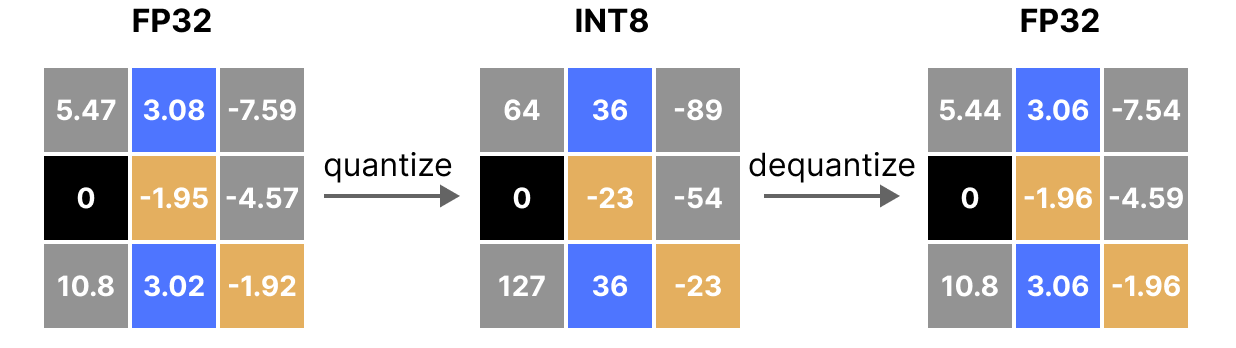
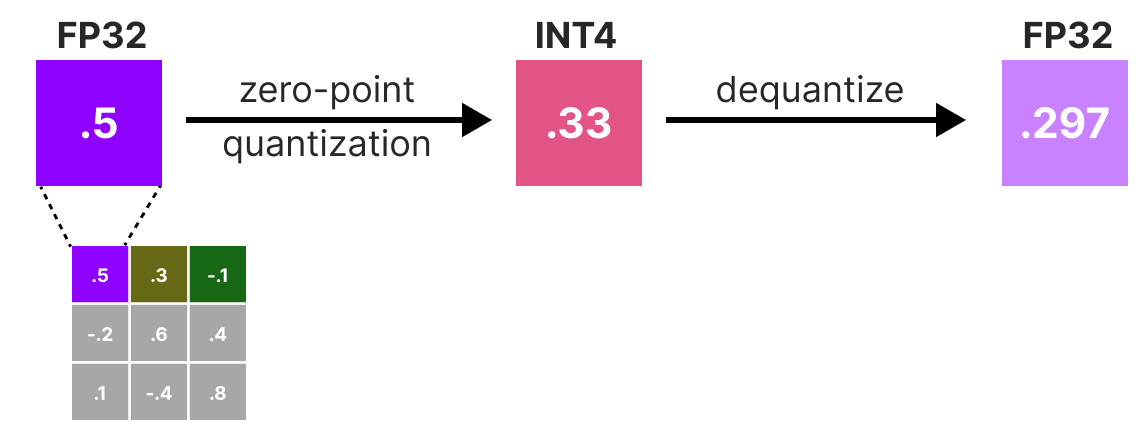
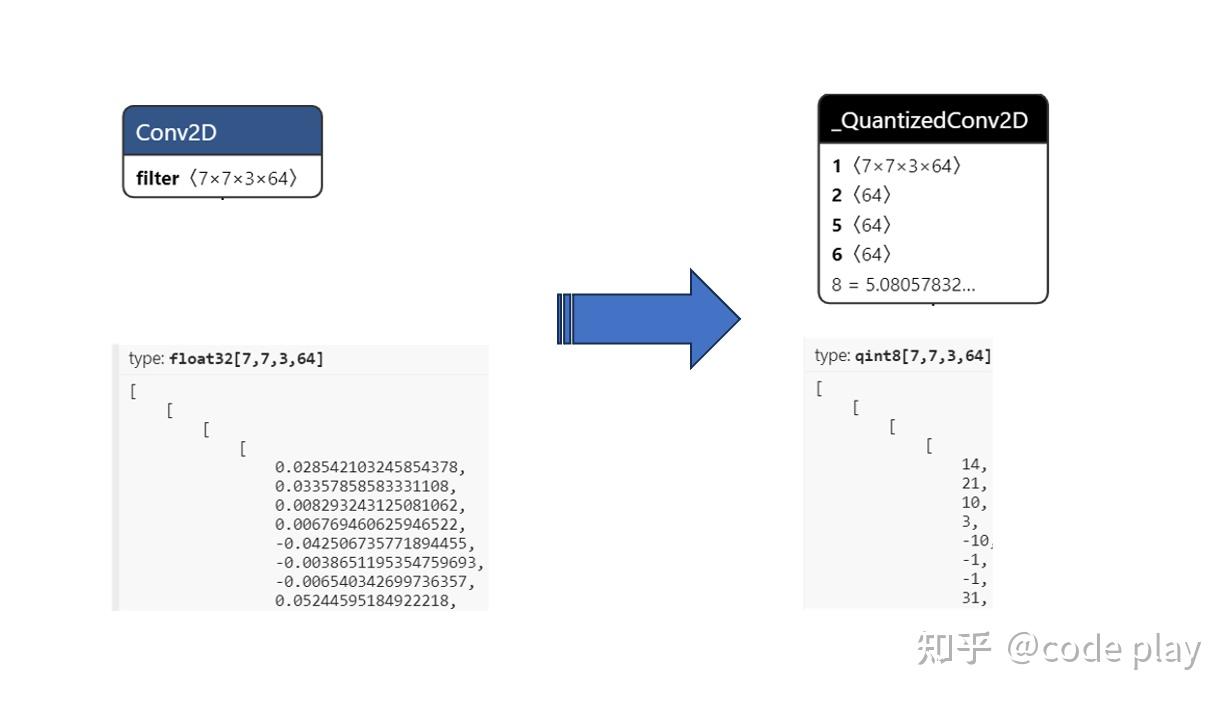
What Is int8 Quantization and Why Is It Popular for Deep Neural ...
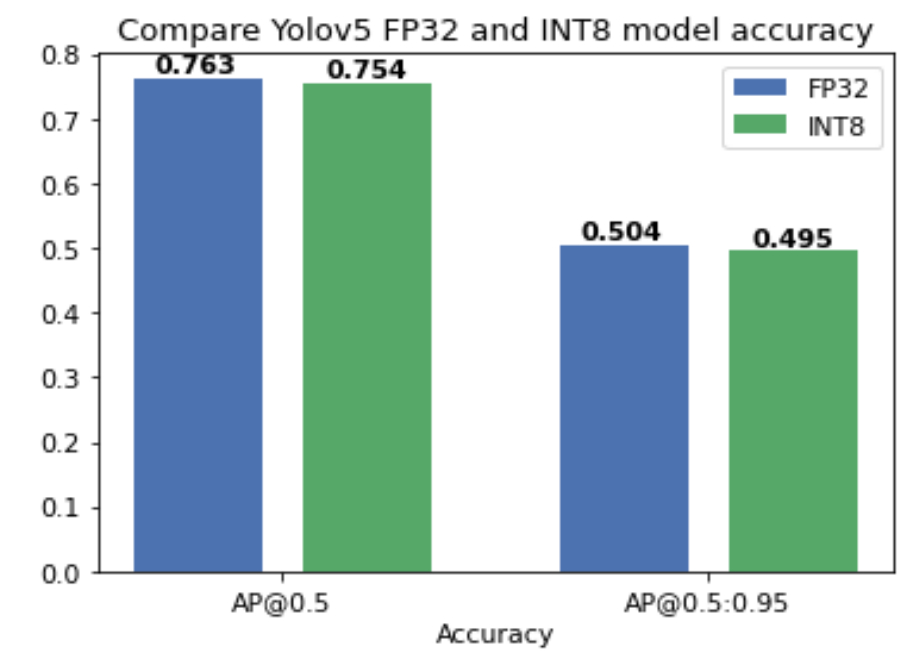
基于OpenVINOTM 2022.1 POT API 实现 YOLOv5 模型 INT8 量化-极市开发者社区
FP32、FP16和INT8_atlas int8 fp16 fp32算力转换-CSDN博客
A model translated with CMSIS_INT8 output format option shows abnormal ...
INT8 Quantization System | Tencent/ncnn | DeepWiki
How to Convert a Custom-Trained YOLO11 Model to a TensorRT INT8 Engine ...
Add print(int8_t) and println(int8_t) to format ASCII digits as with ...
(PDF) FP8 versus INT8 for efficient deep learning inference
TFLite model translated with CMSIS_INT8 output format option shows ...
Swift int8_t, int_fast8_t, int8 difference - Programmer Sought
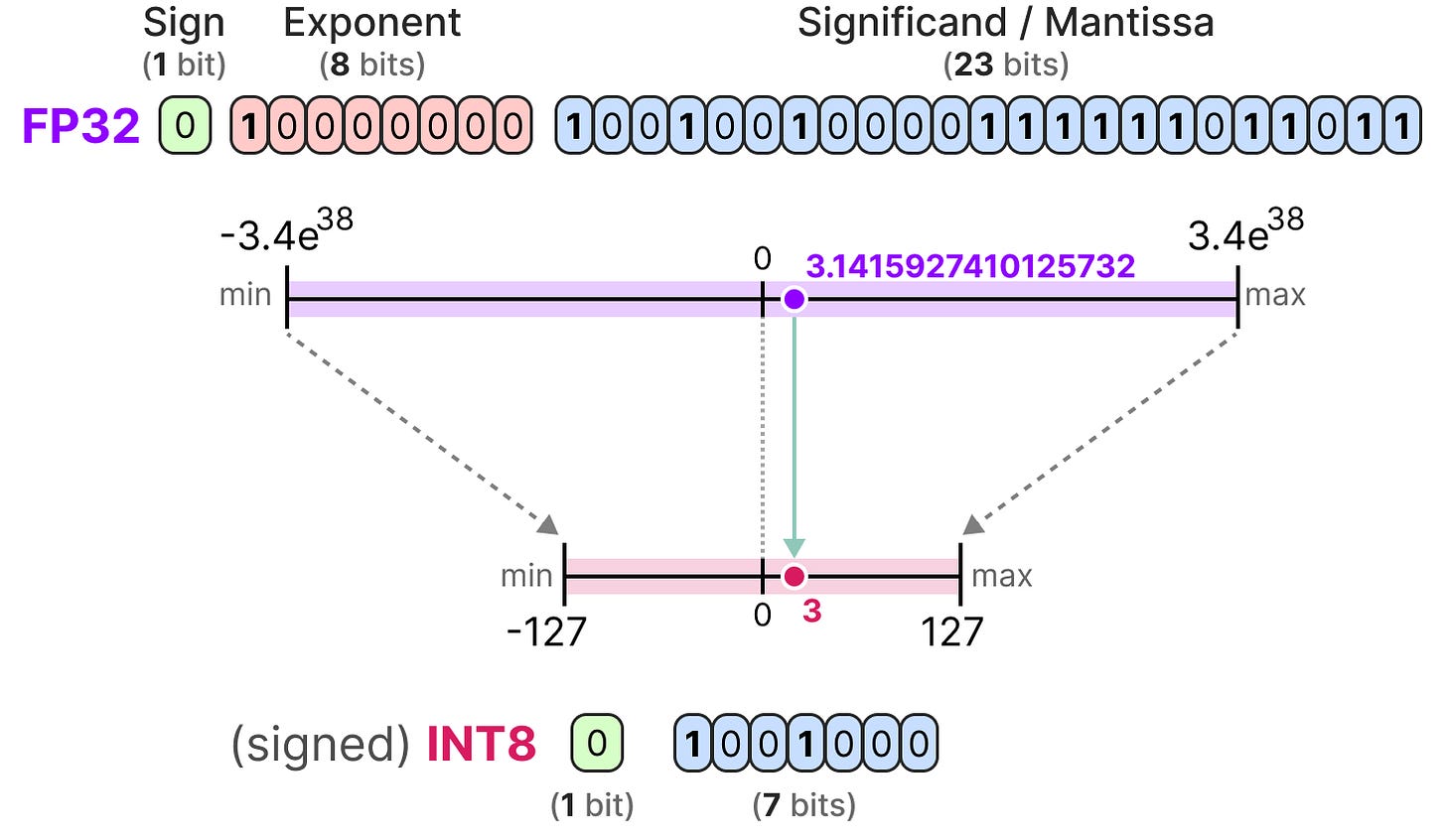
Understanding FP32, FP16, and INT8 Precision in Deep Learning Models ...
c++ inference int8 model error · Issue #16099 · openvinotoolkit ...
L8 and L_INT8 Camera Format Only Uses Red Color Channel · Issue #3168 ...
[Bug]: After 0.6.2 update to 0.6.3, INT8(W8A8) format cannot be loaded ...
Understanding int8 vs fp16 Performance Differences with trtexec ...
Top-1 accuracy of various INT8 methods for ImageNet | Download ...
INT8 Quantization — Intel® Extension for TensorFlow* 0.1.dev1+ge26b4db ...
TensorRT-LLM 低精度推理优化:从速度和精度角度的 FP8 vs INT8 的全面解析 - NVIDIA 技术博客
What Is A Binary Format at Sean Chaffey blog
zai-org/AutoGLM-Phone-9B · Request the INT8 version/求个INT8版本
Data layout of int8 mma with the shape of m8n8k16. | Download ...
Understanding int8 neural network quantization - YouTube
A Hands-On Walkthrough on Model Quantization - Medoid AI
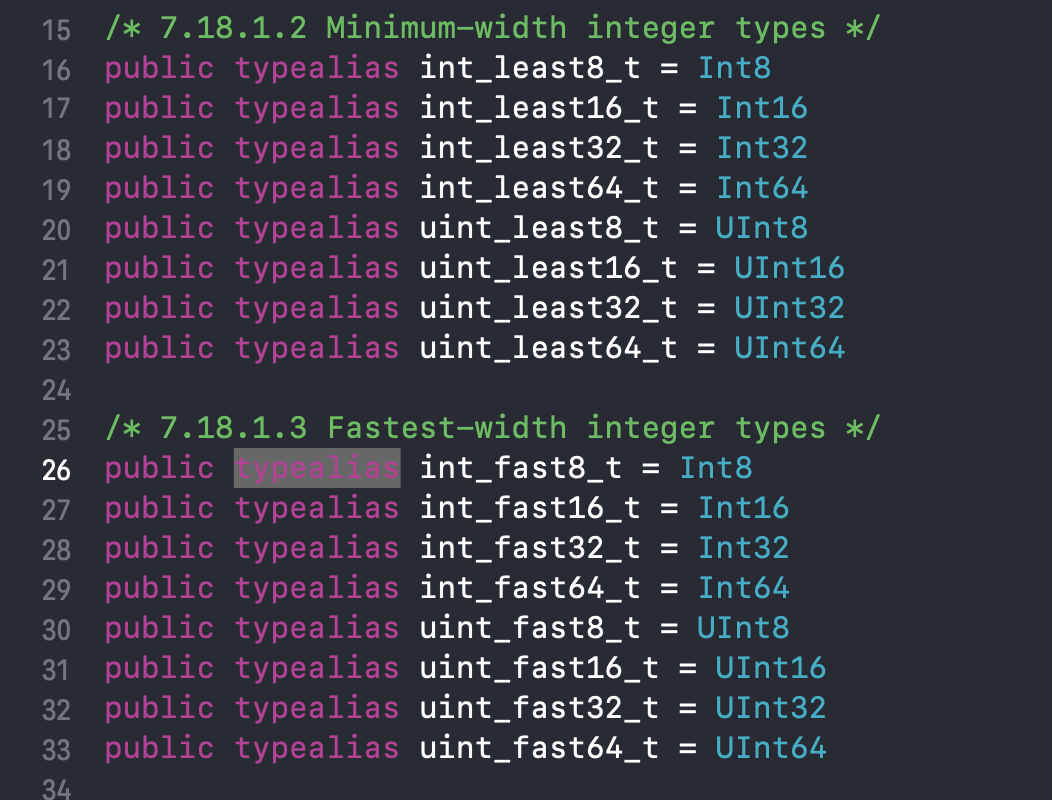
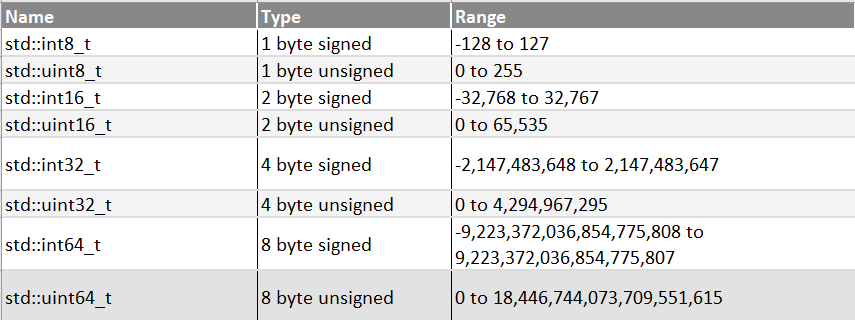
Fixed width integer types (int8) in C++
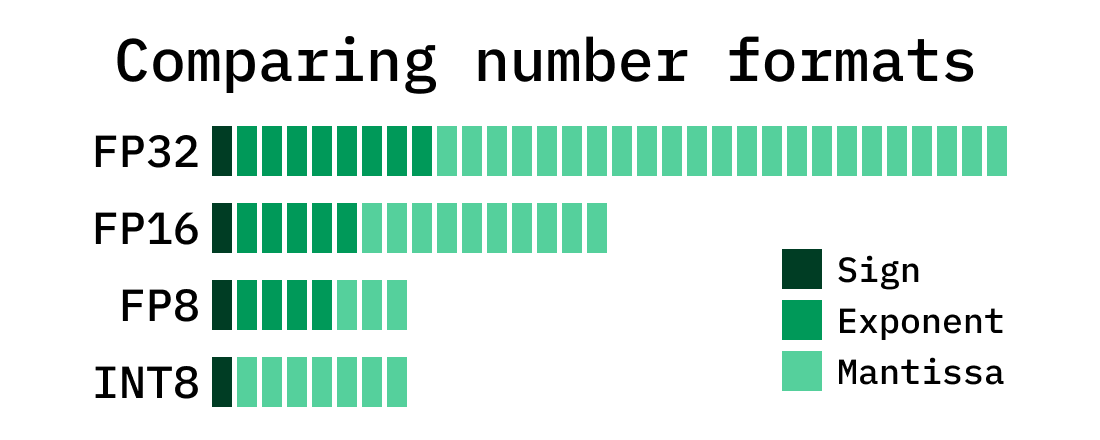
Neural Network Quantization & Number Formats From First Principles
Sparsity in INT8: Training Workflow and Best Practices for NVIDIA ...
Floating-point Arithmetic for AI Inference: Hit or Miss? - Edge AI and ...
Accelerate StarCoder with 🤗 Optimum Intel on Xeon: Q8/Q4 and ...
int8とは - IT用語辞典 e-Words
Quantization Methods for 100X Speedup in Large Language Model Inference
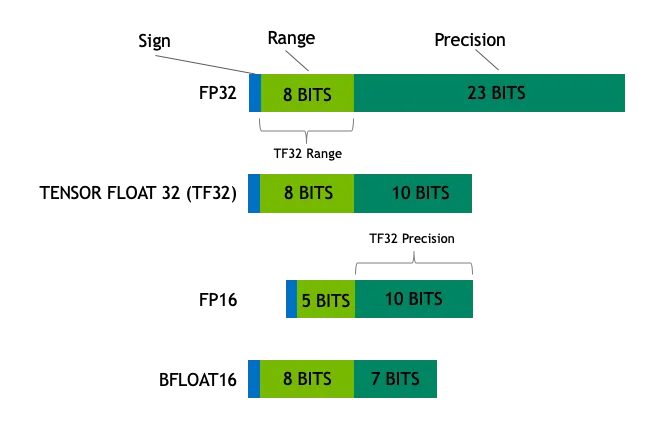
FP8, BF16, and INT8: How Low-Precision Formats Are Revolutionizing Deep ...
iOS 和 swift 中常见的 Int、Int8、Int16、Int32和 Int64介绍「建议收藏」-腾讯云开发者社区-腾讯云
int8_t int16_t int32_t difference,,, int64_t, size_t and the ssize_t ...
Serving Quantized LLMs on NVIDIA H100 Tensor Core GPUs | Databricks
[Video] ប្រើ int8_t uint32_t ក្នុង Arduino ឲ្យបានត្រឹមត្រូវ - etronicskh
部署系列——神经网络INT8量化教程第一讲! - 知乎
小白也能懂!INT4、INT8、FP8、FP16、FP32量化-CSDN博客
深度学习算法优化系列三 | Google CVPR2018 int8量化算法-腾讯云开发者社区-腾讯云
Input data order for "dnn_compute" function generated by CMSIS_INT8 ...
int8_t、uint8_t、__INT 64等和size_t的阐述_uint8头文件-CSDN博客
In-memory data formats — NVDLA Documentation
Floating-point arithmetic for AI inference — hit or miss? | Qualcomm
FP8: Efficient model inference with 8-bit floating point numbers ...
这也许就是DeepSeek V3.1性能提升的关键:UE8M0与INT8量化技术对比与优势分析-阿里云开发者社区
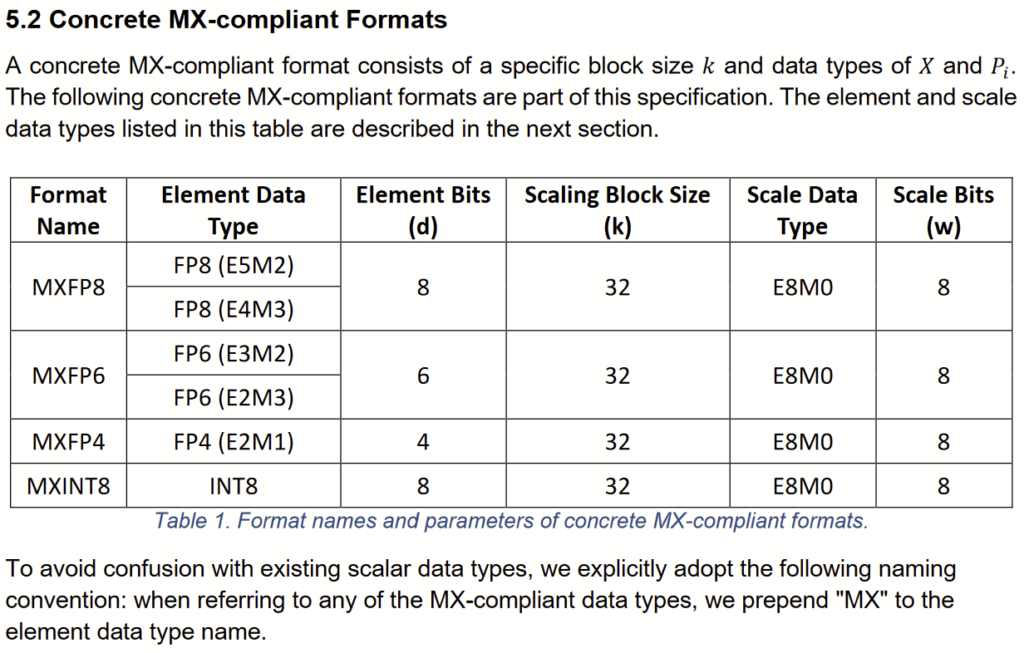
RISC-V Composable Extensions for MX Microscaling Data Formats for AI ...
Using FP8 and FP4 with Transformer Engine — Transformer Engine 2.11.0 ...
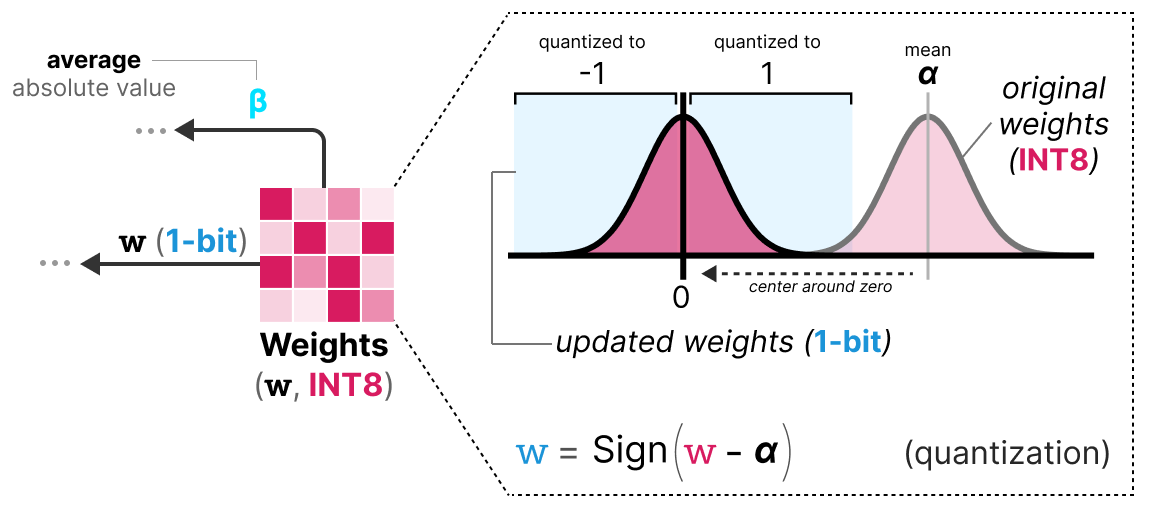
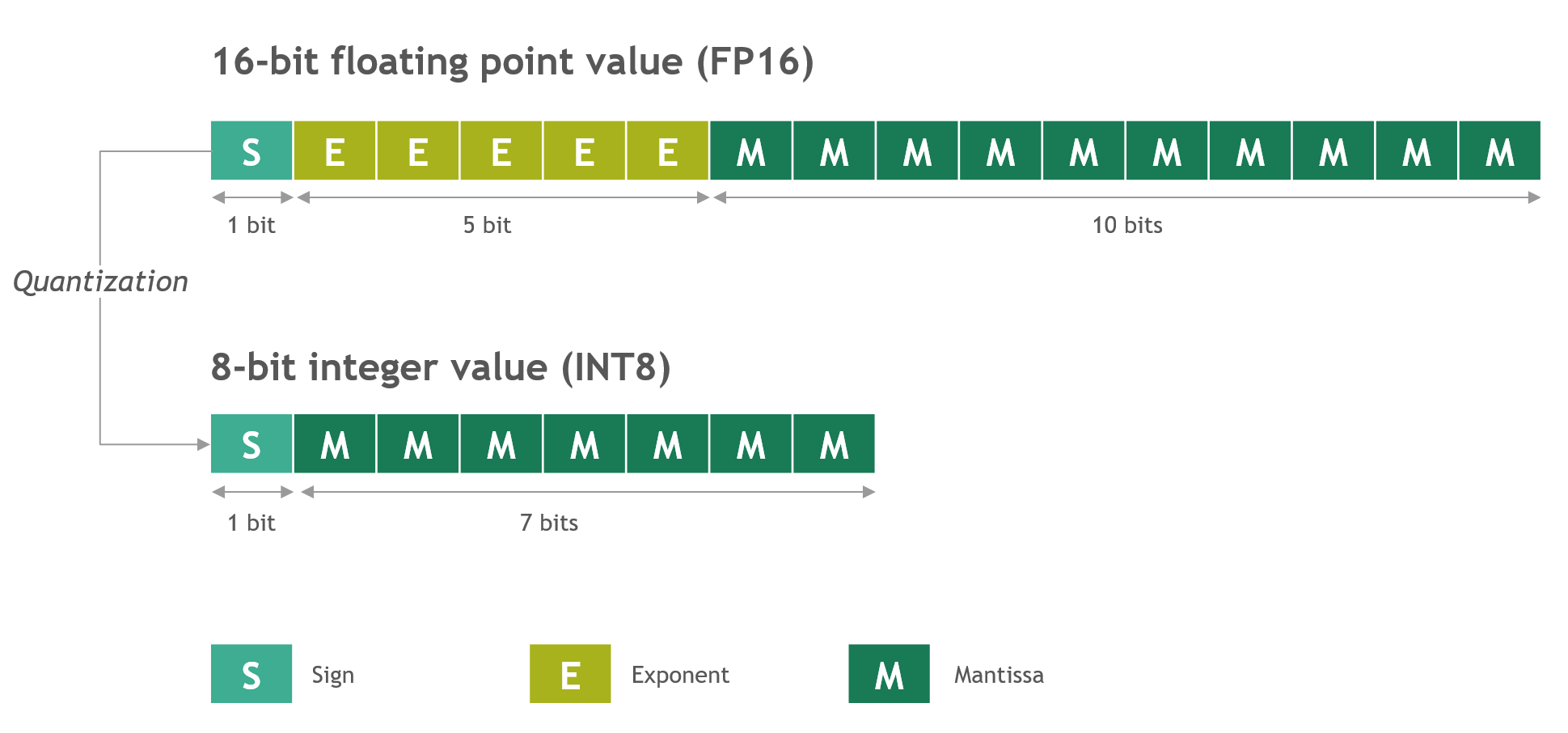
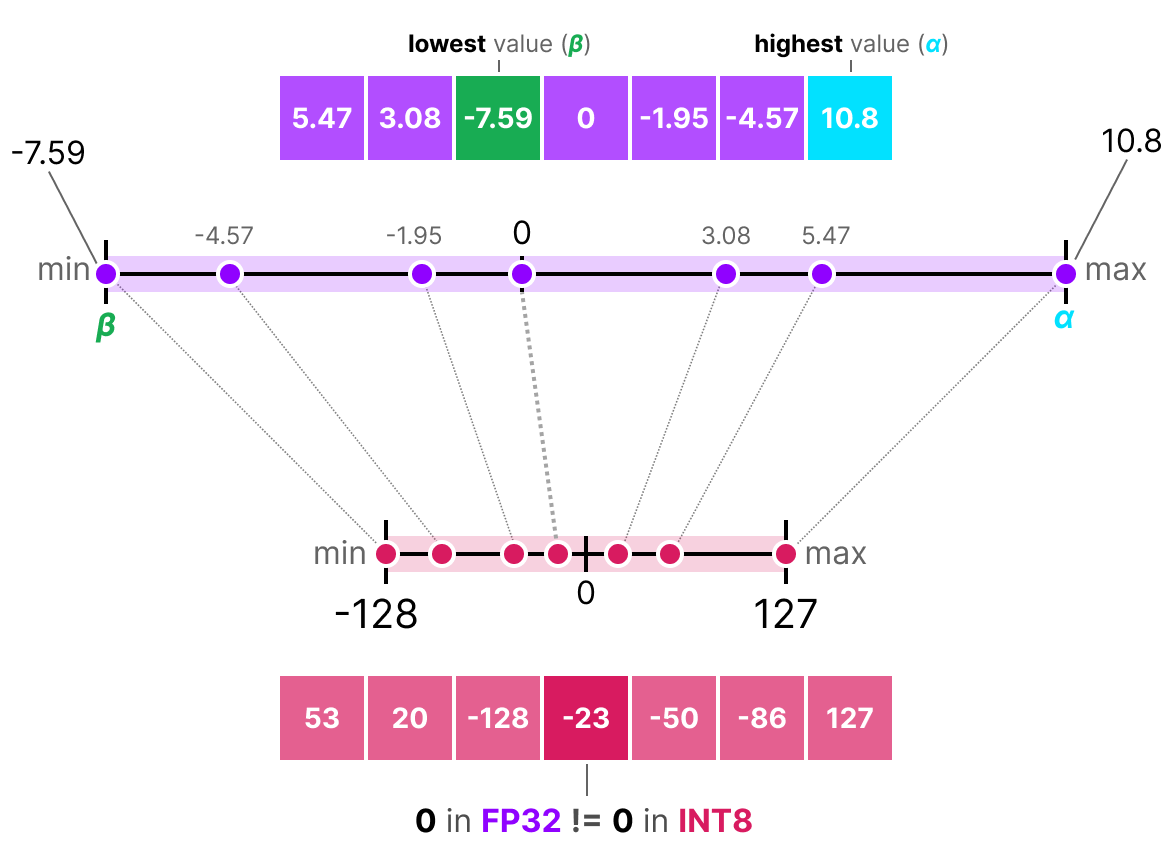
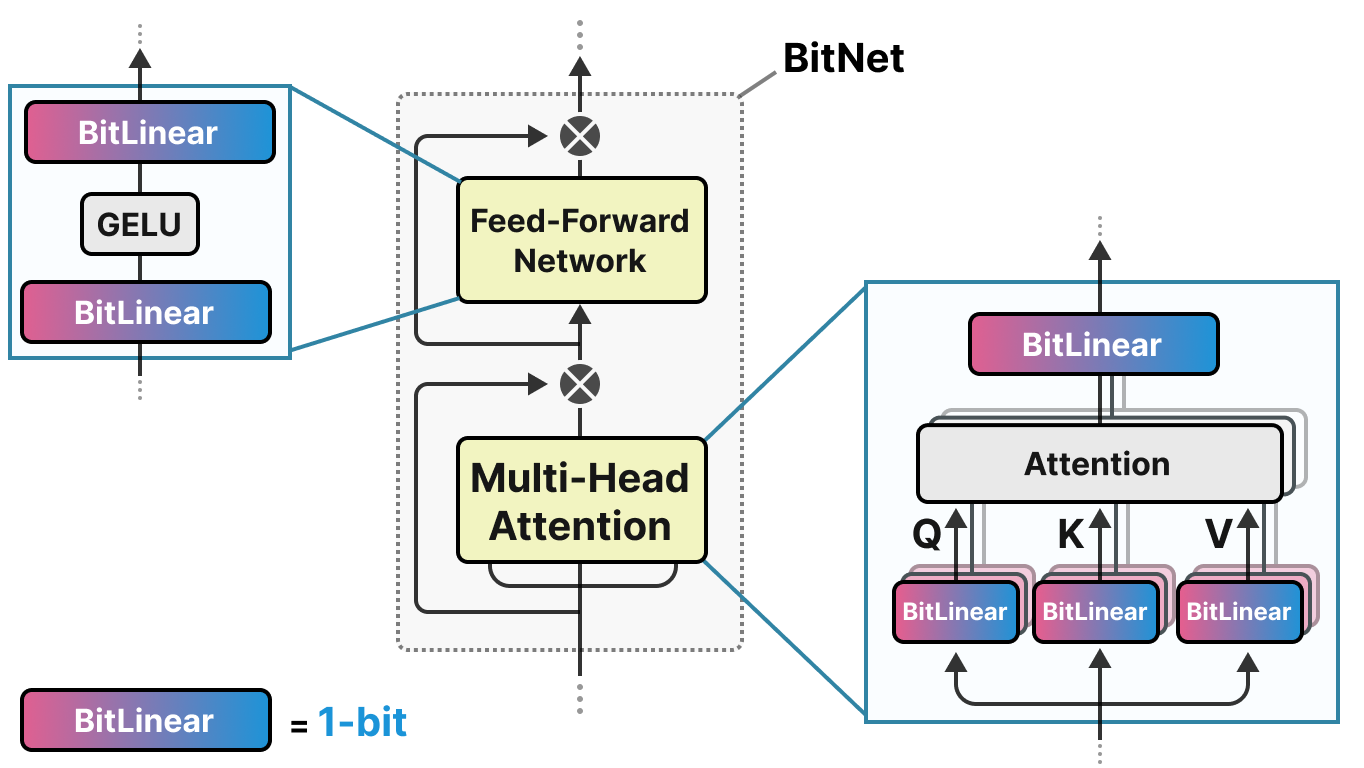
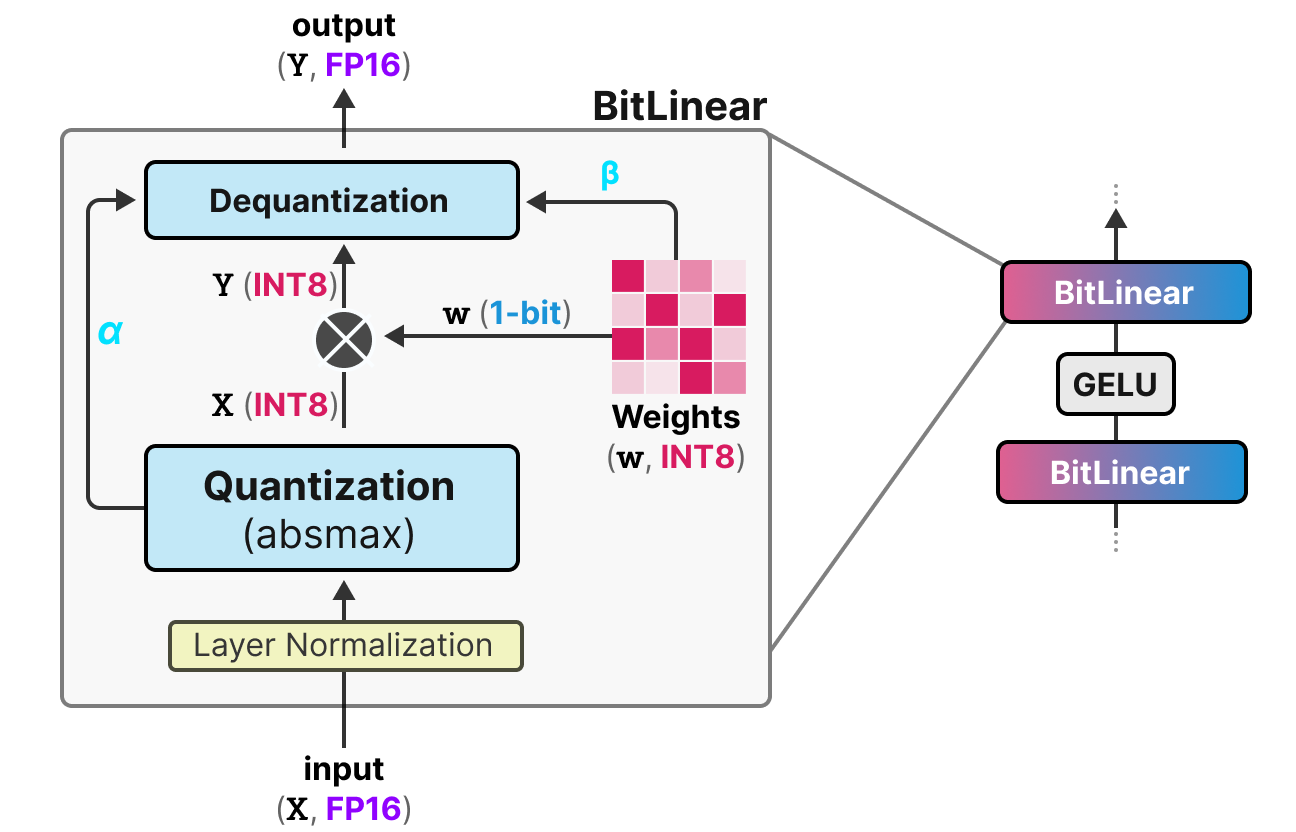
50张图解密大模型量化技术:INT4、INT8、FP32、FP16、GPTQ、GGUF、BitNet_gptq量化-CSDN博客
模型量化(int8)知识梳理 - 知乎
Matlab里的数据类型_matlab中[[是什么数据类型-CSDN博客
5 - Stdint library: uint8_t, int8_t, uint16_t, int16_t, uint32_t, int32 ...
Practical tips for better quantization results - Fritz ai
Facebook AI Researchers Open-Source ‘LLM.int8()’ Tool To Perform ...
详解C语言中的int8_t、uint8_t、int16_t、uint16_t、int32_t、uint32_t、int64_t、uint64 ...
大语言模型的模型量化(INT8/INT4)技术-CSDN博客
Left: Unsigned INT4 quantization compared to unsigned FP4 2M2E ...
大模型 LLM.int8() 量化技术原理与代码实现-51CTO.COM
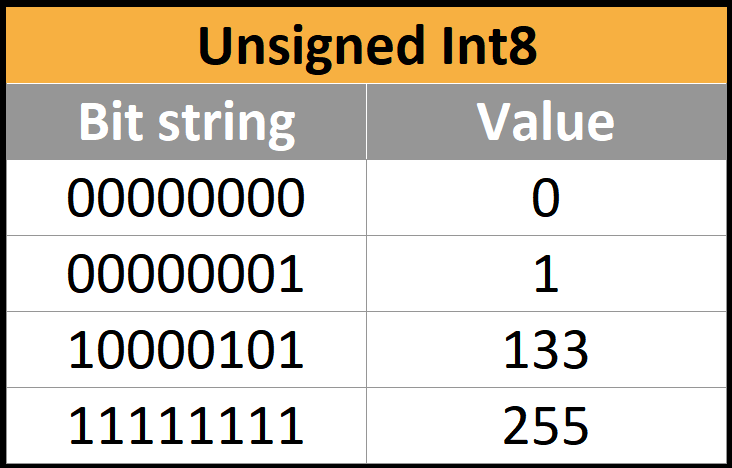
int8取值范围的原码反码补码实现原理-开发者社区-阿里云
Unlocking LLM Performance: Advanced Quantization Techniques on Dell ...
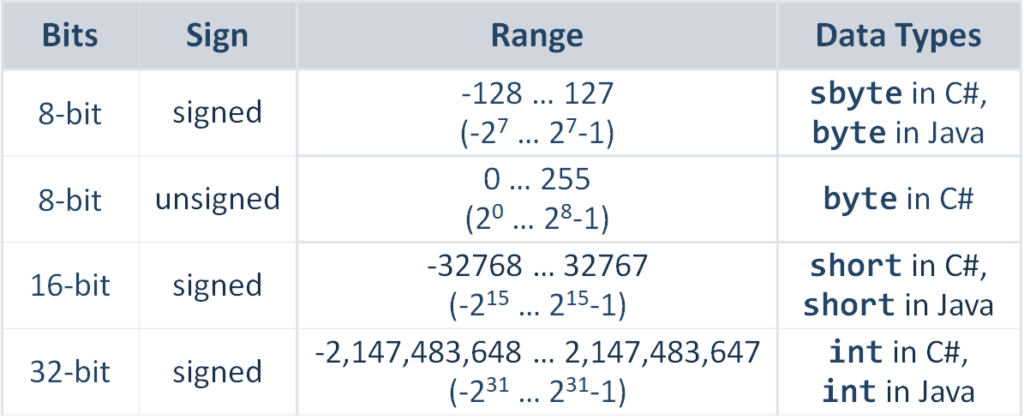
Bits, Bytes and Integers——二进制unsigned以及Two-complement表示,十六进制_2 byte ...
matlab将数据转换为int8类型 - 知乎
Running Llama 2 on CPU Inference Locally for Document Q&A | Towards ...
Matlab中typecast函数由int8转换为int32_y = typecast(u,'uint8');-CSDN博客
pandas-数据处理之节省内存 - 知乎
(PDF) Understanding INT4 Quantization for Transformer Models: Latency ...
Czy matematyka z DSP może pomóc pokonać procesor graficzny pod kątem ...
Arduino: int VS uint8_t VS uint16_t - YouTube
TAO 5.0.0-tf1.15.5 support for .tlt , .etlt, .hdf5, .onnx, .engine ...
jncraton/MiniCPM-2B-dpo-bf16-llama-format-ct2-int8 at main
所谓INT8量化 - 知乎
Int8量化算子在移动端CPU的性能优化-阿里云开发者社区
Data Representation in Computer Memory [Dev Concepts #33] - SoftUni Global
Arm Programming in C Chapter 7 - ppt download
[R] LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale ...
从0开始的视觉研究生涯(6)YOLOv8-seg实战应用NCNN加速详解(进阶,多线程、Int8量化)_yolov8seg ocr-CSDN博客